
Какие типы содержатся в реляционных базах данных

РЕЛЯЦИОННАЯ
БАЗА ДАННЫХ И ЕЕ ОСОБЕННОСТИ. ВИДЫ СВЯЗЕЙ МЕЖДУ РЕЛЯЦИОННЫМИ ТАБЛИЦАМИ
Реляционная
база данных — это совокупность взаимосвязанных таблиц, каждая
из которых содержит информацию об объектах определенного типа. Строка
таблицы содержит данные об одном объекте (например, товаре, клиенте),
а столбцы таблицы описывают различные характеристики этих объектов — атрибутов
(например, наименование, код товара, сведения о клиенте). Записи, т. е.
строки таблицы, имеют одинаковую структуру — они состоят из полей, хранящих
атрибуты объекта. Каждое поле, т. е. столбец, описывает только одну характеристику
объекта и имеет строго определенный тип данных. Все записи имеют одни
и те же поля, только в них отображаются различные информационные свойства
объекта.
В реляционной базе
данных каждая таблица должна иметь первичный ключ — поле или комбинацию
полей, которые единственным образом идентифицируют каждую строку таблицы.
Если ключ состоит из нескольких полей, он называется составным. Ключ должен
быть уникальным и однозначно определять запись. По значению ключа можно
отыскать единственную запись. Ключи служат также для упорядочивания информации
в БД.
Таблицы реляционной
БД должны отвечать требованиям нормализации отношений. Нормализация
отношений
— это формальный аппарат ограничений на формирование таблиц, который
позволяет устранить дублирование, обеспечивает непротиворечивость
хранимых
в базе данных, уменьшает трудозатраты на ведение базы данных.
Пусть создана таблица
Студент, содержащая следу-рэщие поля: № группы, ФИО, № зачетки, дата рождения,
шазвание специальности, название факультета. Такая организация хранения
информации будет иметь ряд недостатков:
- дублирование информации
(наименование специальности и факультета повторяются для каждого студента),
следовательно, увеличится объем БД; - процедура обновления
информации в таблице затрудняется из-за необходимости редактирования
каждой записи
таблицы.
Нормализация таблиц
предназначена для устранения этих недостатков. Имеется три нормальные
формы отношений.
Первая нормальная
форма. Реляционная таблица приведена к первой нормальной форме тогда
и только тогда, когда ни одна из ее строк не содержит в любом своем поле
более одного значения и ни одно из ее ключевых полей не пусто. Так, если
из таблицы Студент требуется получать сведения по имени студента, то поле
ФИО следует разбить на части Фамилия, Имя, Отчество.
Вторая нормальная
форма. Реляционная таблица задана во второй нормальной форме, если
она удовлетворяет требованиям первой нормальной формы и все ее поля, не
входящие в первичный ключ, связаны полной функциональной зависимостью
с первичным ключом. Чтобы привести таблицу ко второй нормальной форме,
необходимо определить функциональную зависимость полей. Функциональная
зависимость полей — это зависимость, при крторой в экземпляре информационного
объекта определенному значению ключевого реквизита соответствует только
одно значение описательного реквизита.
Третья нормальная
форма. Таблица находится в третьей нормальной форме, если она удовлетворяет
требованиям второй нормальной формы, ни одно из ее неключевых полей не
зависит функционально от любого другого неключевого поля. Например, в
таблице Студент (№ группы, ФИО, № зачетной книжки, Дата рождения, Староста)
три поля — № зачетной книжки, № группы, Староста находятся в транзитивной
зависимости. № группы зависит от № зачетной книжки, а Староста зависит
от № группы. Для устранения транзитивной зависимости необходимо часть
полей таблицы Студент перенести в другую таблицу Группа. Таблицы примут
следующий вид: Студент (№ группы, ФИО, № зачетной книжки, Дата рождения),
Группа (№ группы, Староста).
Над реляционными
таблицами возможны следующие операции:
- Объединение таблиц
с одинаковой структурой. Результат— общая таблица: сначала первая, затем
вторая (конкатенация). - Пересечение таблиц
с одинаковой структурой. Результат — выбираются те записи, которые находятся
в обеих таблицах. - Вычитание таблиц
с одинаковой структурой. Результат — выбираются те записи, которых нет
в вычитаемом. - Выборка (горизонтальное
подмножество). Результат — выбираются записи, отвечающие определенным
условиям. - Проекция (вертикальное
подмножество). Результат — отношение, содержащее часть полей из исходных
таблиц. - Декартово произведение
двух таблиц Записи результирующей таблицы получаются путем объединения
каждой записи первой таблицы с каждой записью другой таблицы.
Реляционные таблицы
могут быть связаны друг с другом, следовательно, данные могут извлекаться
одновременно из нескольких таблиц. Таблицы связываются между собой для
того, чтобы в конечном счете уменьшить объем БД. Связь каждой пары таблиц
обеспечивается при наличии в них одинаковых столбцов.
Существуют следующие
типы информационных связей:
- один-к-одному;
- один-ко-многим;
- многие-ко-многим.
Связь один-к-одному
предполагает, что одному атрибуту первой таблицы соответствует только
один атрибут второй таблицы и наоборот.
Связь один-ко-многим
предполагает, что одному атрибуту первой таблицы соответствует несколько
атрибутов второй таблицы.
Связь многие-ко-многим
предполагает, что одному атрибуту первой таблицы соответствует несколько
атрибутов второй таблицы и наоборот.
Источник
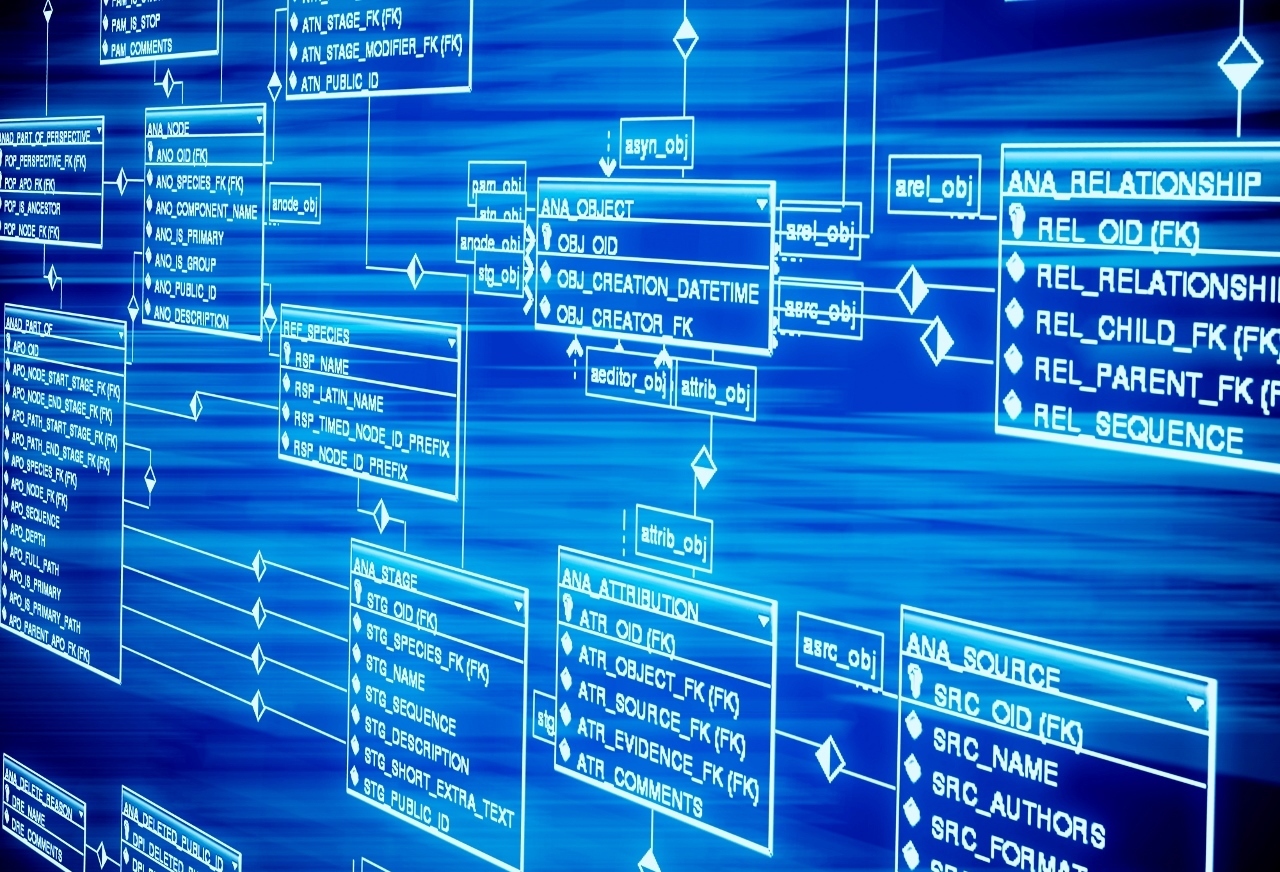
В этой статье мы изучим особенности и структуру реляционных данных, а также увидим пример создания этих БД. Рассмотрим проектирование, составим концептуальную модель данных. Узнаем, что такое объект и нормализация данных, обсудим, на что обратить внимание на этапе проектирования баз данных. Скучно не будет!
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
– столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
– в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
– каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
– на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
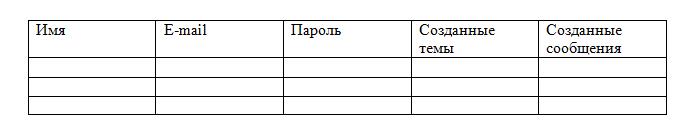
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
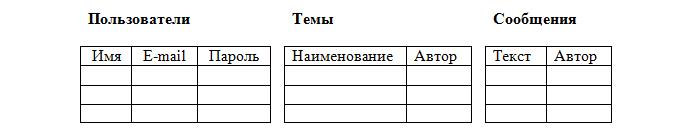
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
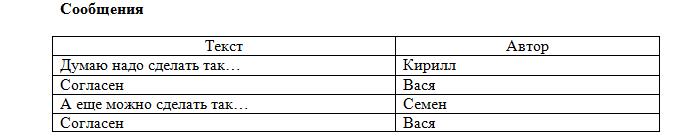
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Например, для таблицы «Пользователи» первичным ключом может быть столбец e-mail, т. к. не бывает 2-х пользователей с одним и тем же e-mail.
На практике для хранения и обработки данных рекомендуют применять суррогатные ключи (их использование позволит абстрагировать РК от реальных данных). Это важно, если пользователь, вдруг, сменит e-mail, а ведь первичные ключи нельзя менять.
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:

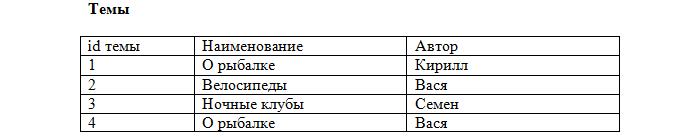
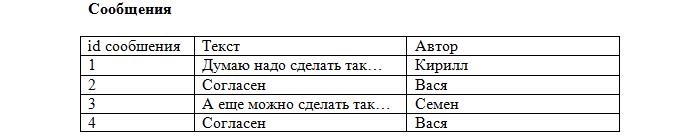
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
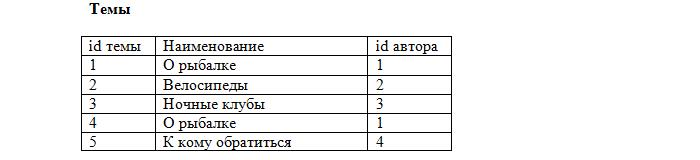
Ещё момент: допустим, добавляется новый пользователь по имени Вася.

Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:

Итак, наша база данных фактически готова. Схематично она выглядит так:
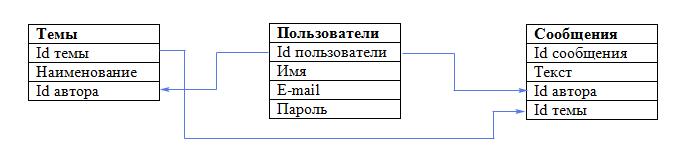
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
– вещи обозначаются прямоугольниками;
– атрибуты объекта овалами;
– связи в таблицах ромбами;
– мощность и направление связей стрелками (одинарными, двойными).
Простой пример — интернет-магазин. В нём есть товары, поставляемые поставщиками и заказываемые покупателями. Это три объекта и две связи:

Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
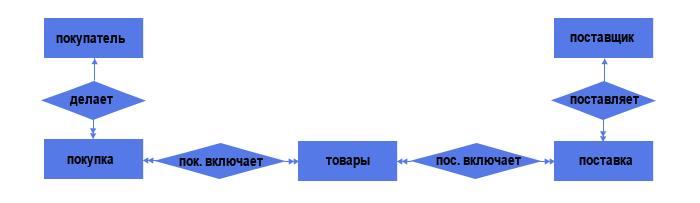
Итого 5 объектов и 4 связи. Из них:
– 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
– 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Атрибуты таблицы
Каждый объект интернет-магазина имеет свои атрибуты:
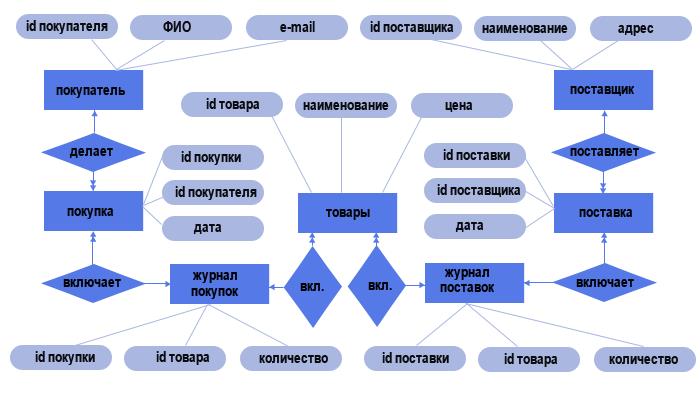
В результате мы создали концептуальную модель будущей базы данных. Точнее говоря, речь идёт лишь о части БД, т. к. мы не учли склады, сотрудников и т. п. Собственно, при обширной предметной области данные лучше разбить на несколько локальных областей. Как правило, объём должен быть в пределах 5-7 объектов. И лишь после создания локальных моделей выполняется их объединение в общую сложную схему. В нашем случае ограничимся созданной моделью. Однако теперь давайте преобразуем её в реляционную модель данных.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
– построение набора предварительных таблиц;
– указание РК;
– выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
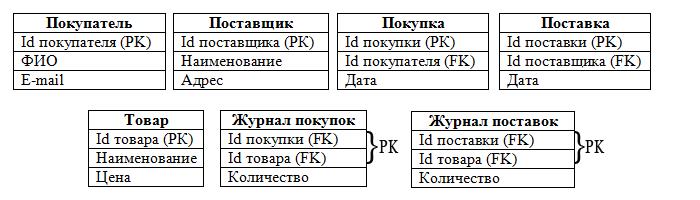
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
– 1-й нормальной формы (1НФ);
– 2НФ;
– 3НФ;
– НФБК (нормальной формы Бойса-Кодда);
– 4НФ;
– 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии. Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
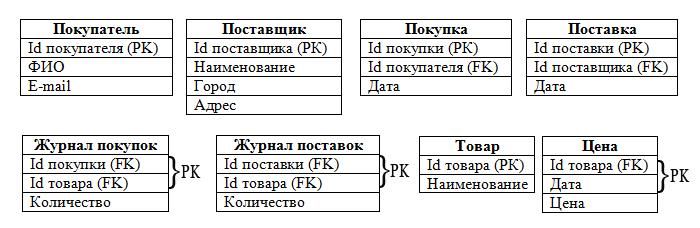
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Подводим итоги проектирования
Проектирование БД — процесс небыстрый и достаточно трудоёмкий. Во время проектирования надо хорошо знать предметную область, учитывать все нюансы. Вся информация должна отображаться в виде таких элементов, как объекты, атрибуты, связи, причём проектирование успешно лишь тогда, когда всё сделано максимально рационально.
Вообще, взгляды на проектирование среди разработчиков могут различаться. Некоторые игнорируют теорию, руководствуясь лишь опытом и здравым смыслом. Другие во время проектирования отводят главную роль интуиции, считая проектирование искусством, которым владеют далеко не все. Как бы там ни было, знания никогда не бывают лишними.
Да, реляционная база данных — это не более чем хранилище, где хранятся данные. Однако от того, как грамотно вы его организуете, будет зависеть стабильность работы всего приложения, где используются эти самые данные.
В заключение, добавим, что умение проектировать базы вам никогда не помешает. А научиться всему этому вы сможете на нашем курсе «Реляционные СУБД». Ждём вас!
Источник

Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.
- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.

Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
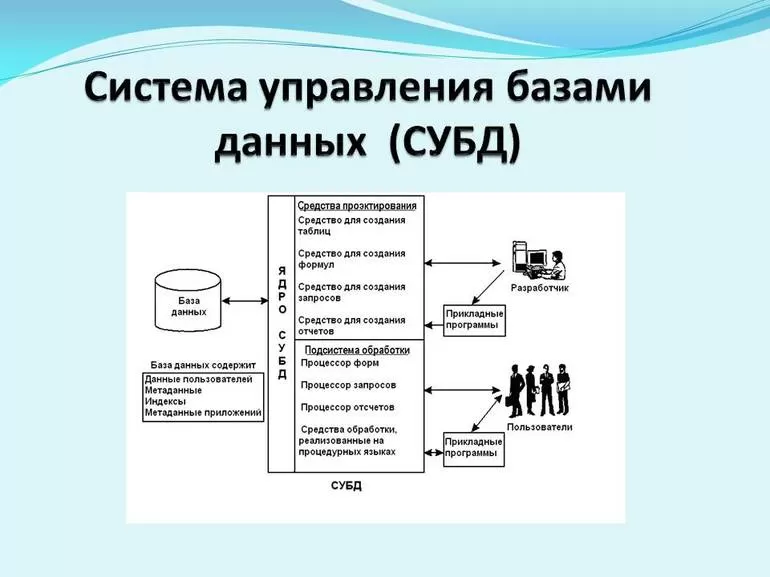
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:

- Первая стадия — это анализ требований. Разработчик должен разрешить главные проблемы: какие элементы данных будут содержаться, как и кто должен к ним обращаться.
- В следующей стадии проектируется логическая структура БД.
- В завершающей стадии проектирования логическая структура БД трансформируется в физическую. Элементы данных определяются как табличные столбцы.
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
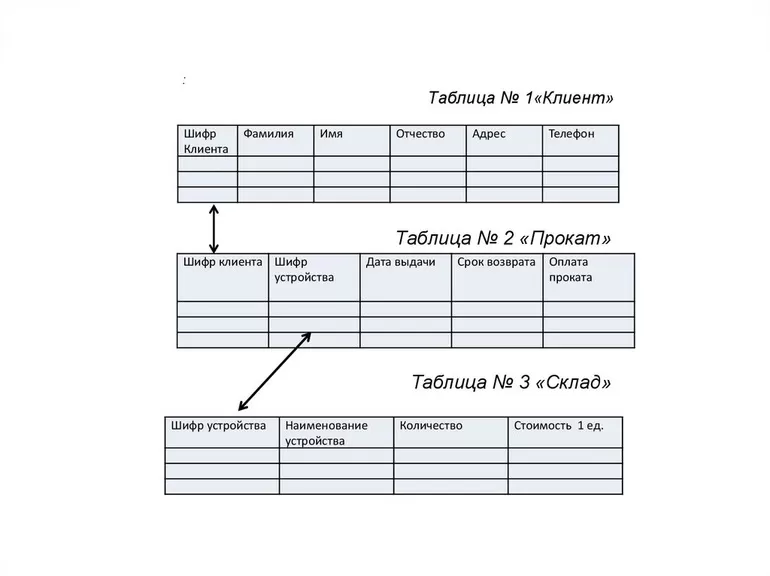
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.

Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Источник