
В бите какое двоичное число содержится


Для полноты понимания работы микроконтроллера необходимо четко знать, что такое бит и байт, а также уметь применять различные системы счисления.
Основным вычислительным ядром любого микроконтроллера является микропроцессор. Именно он выполняет обработку команд или же кода, написанного программистом.
Упрощенно работу микропроцессора можно представить следующим образом. Сначала выполняется считывание данных из определенной ячейки памяти, далее выполняется их обработка и затем возвращение результата назад в ячейку памяти. Следовательно, для того, чтобы микропроцессор мог выполнять свои функции необходимо наличие памяти. Иначе ему неоткуда будет считывать данные, а затем некуда помещать результаты вычислений.
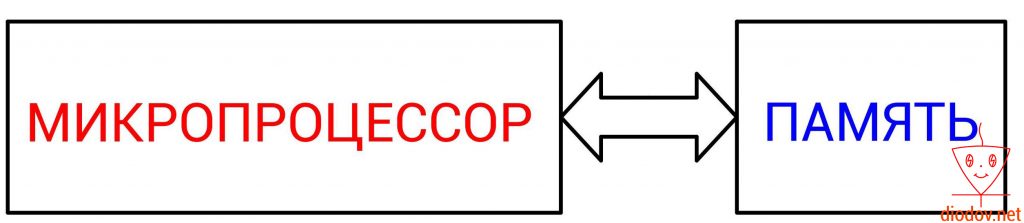
Давайте кратко рассмотрим алгоритм работы микропроцессора (МП) на примере сложения двух цифр.
- Сначала МП считывает значение одного числа по указанному адресу ячейки памяти.
- Далее он считывает другое значение из второй ячейки.
- Складывает оба значения.
- Возвращает их суму в ячейку памяти.
Вот такой монотонной работой занимаются микропроцессоры. Для выполнения одной команды ему необходимо выполнить четыре операции. Однако современные МП выполняют более 1 000 000 000 операций за одну секунду. Микроконтроллеры же выполняют более 1 000 000 операций, чего, как правило, предостаточно для такого крохотного устройства.
Данные, с которыми оперирует микропроцессор, представляют собой набор цифр. Поэтому нашей целью является рассмотреть, какие цифры, а точнее системы счисления “понимает” микроконтроллер.
Десятичная система счисления
Десятичная система счисления нам очень близка и понятна. Возникла она очень давно, когда у людей впервые возникал необходимость подсчета чего-либо, например количества дней или определённых событий. Поскольку в те давние времена не было каких-либо технических устройств, то люди использовали для счета пальцы рук. Загибая или разгибая пальцы можно получить десять комбинаций, что очень просто и наглядно.
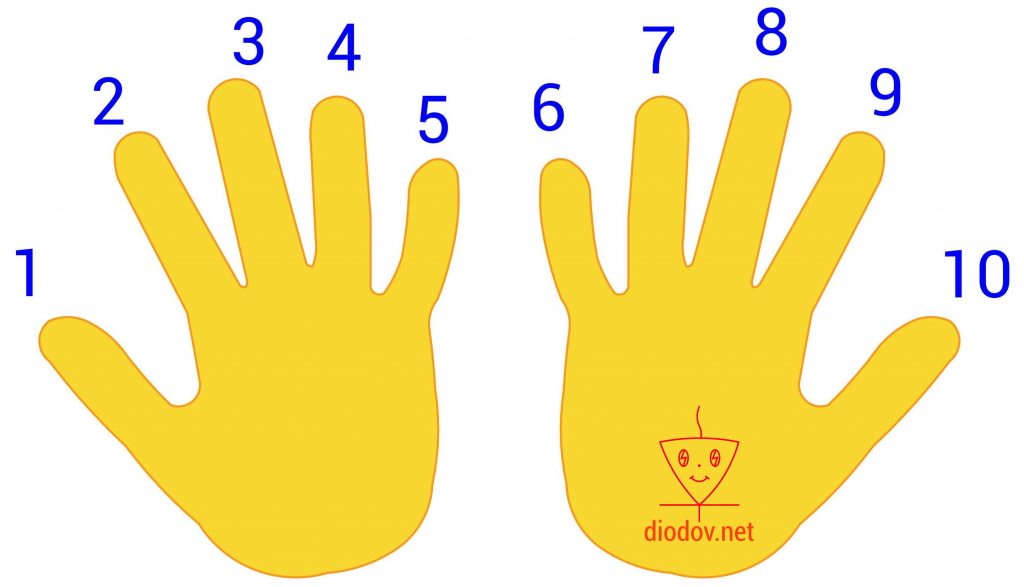
Математически данная она состоит из десяти разных символов 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, поэтому она и называется десятичной. С помощью указанных символов легко отобразить любое число.
Основанием десятичной системы является 10. Когда при счете использованы все знаки от 0 до 9, то, чтобы продолжить дальнейший счет, необходимо вместо символа 9 поставить символ 0, т. е. обнулить предыдущее значение, а слева от нуля записать символ 1. И так можно продолжать счет до бесконечности, прибавляя слева от текущей позиции цифры последующую.
Каждая позиция цифры имеет свой вес. Наименьший вес имеет позиции, находящаяся в крайнем правом положении. По мере перемещения слева на право, вес позиции возрастает.
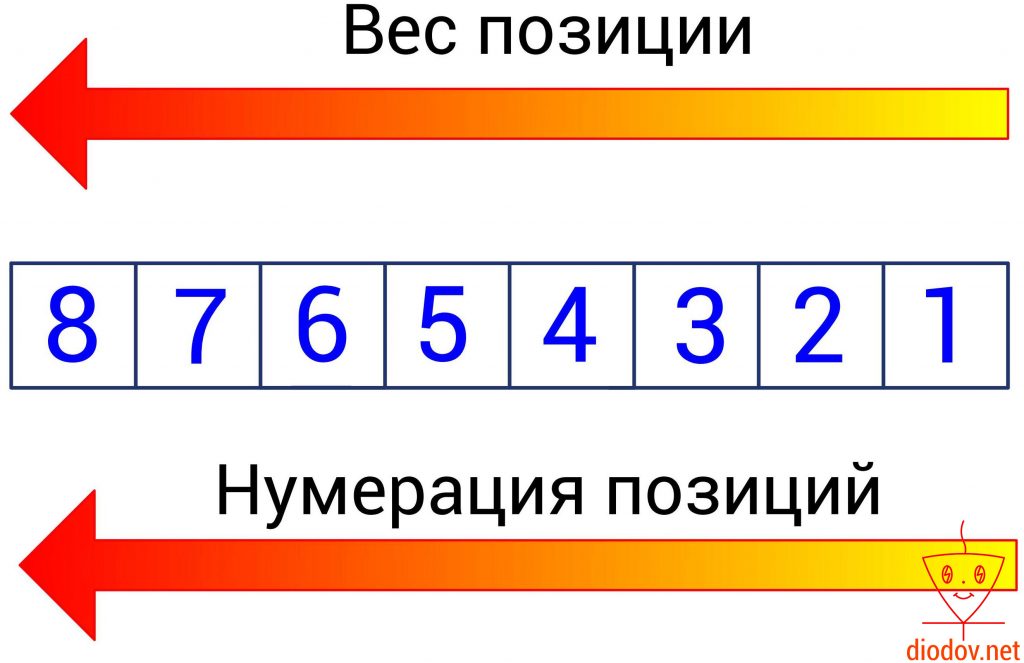
Например, число 2345 имеет 4 позиции. В крайней левой позиции отображаются единицы, в данном случае 5 единиц, а степень 10 имеет нулевое значение. Далее вес позиции увеличивается. Следующее значение, расположенное слева от предыдущего, уже содержит десятки, а 10 имеет степень 1, поэтому во второй позиции числа 2345 четыре десятка.
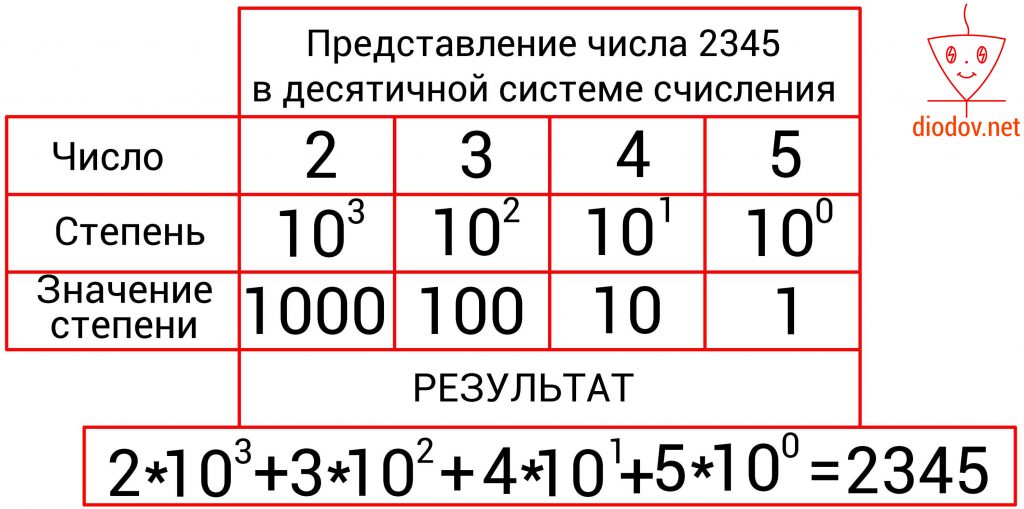
Далее перемещаемся по разрядам 2345 справа налево и увеличиваем степень 10 еще на одну единицу, т. е. имеем 102. Соответственно получаем три сотни. И последняя цифра, она же первая по счету, если считать слева на право, имеет наибольший вес для, т. е. 103, и поэтому имеем 2000. Чтобы получить окончательный результат, следует сложить количество значений цифр всех позиций.
Двоичная система счисления
Двоичная система счисления оперирует всего лишь двумя символами и 1. Она повсеместно применяется в цифровой технике, поскольку очень удачно сочетается с двумя устойчивыми состояниями электрической цепей: включено и выключено либо есть сигнал и нет сигнала. Также нулем еще обозначают сигнал низкого уровня, а единицей – высокого.
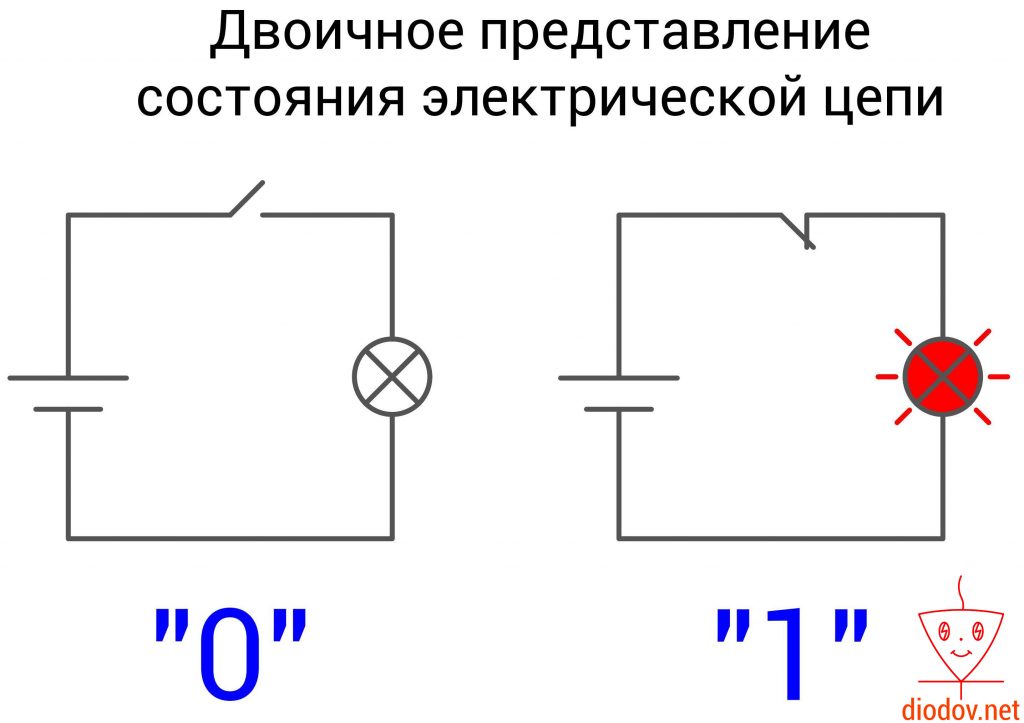
Порядок записи двоичного числа полностью соответствует десятичному. Веса позиций также возрастают справа налево. Только основанием является 2, а не 10.
Чтобы отличать двоичную систему от десятичной в цифровой технике используют индекс 2 и 10 соответственно:
11012 – двоичное;
110110 – десятичное.
При написании кода программы для обозначения двоичного значения перед ним ставится префикс b, например 0b11010101. Если записывается десятичное, то перед ним ничего не ставится.
b11010101 – двоичное;
11010101 – десятичное.
Бит и байт
Двоичная система счисления также используется при хранении и обработке информации.
Вся информация цифровых запоминающих устройств хранится в памяти. Память представляет собой набор ячеек.
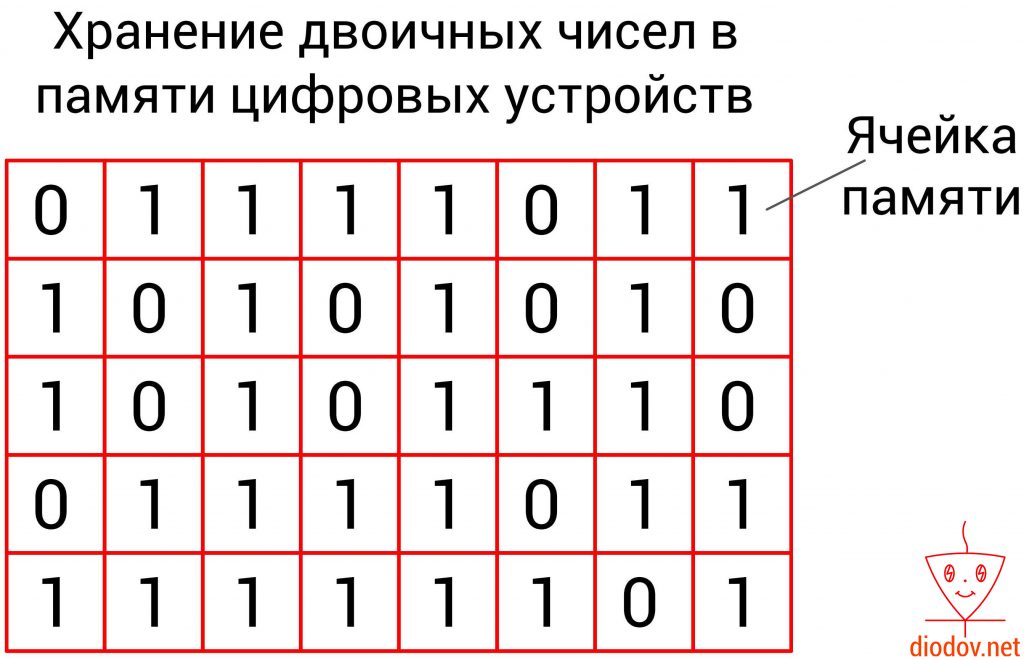
Каждая ячейка содержит один бит данных. Бит – это единица измерения объема памяти. В одном бите можно запоминать максимум два значения: 0 – это одно значение, а 1 – второе.
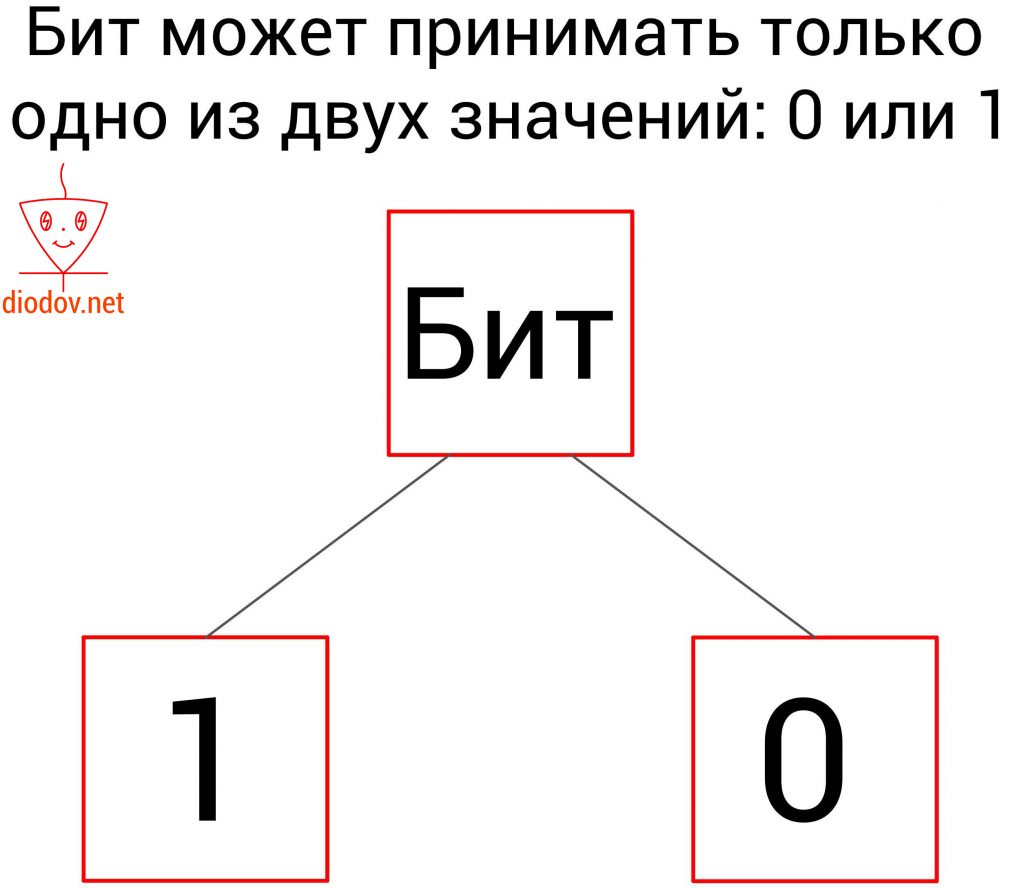
Bit происходит от двух английских слов Binary Digit (двоичное число).
При работе с битами регистров микроконтроллера мы будем часто обращаться к таким понятиям, как старший и младший биты. Эти понятия строго регламентированы. В двоичной системе разряд, который имеет самую правую позицию, получил название младший значащий бит (МЗБ). В англоязычной литературе его называют Least Significant Bit (LSB). Именно с него начинается нумерация битов.

Наибольший вес имеет бит, находящийся в самой левой ячейке памяти. Его принято называть старший значащий бит (СЗБ) или Most Significant Bit – MSB.
Более емкой единицей информации является байт (byte). Он равен 8 битам, т. е. восемь элементарных ячеек памяти составляют один байт.
1 байт = 8 бит
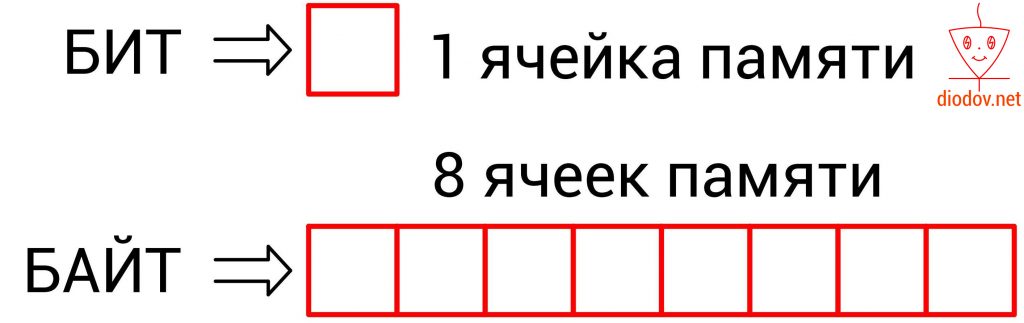
В одном бите можно хранить только два разных значения или две комбинации. А в 1 байте можно хранить 256 различных комбинаций. Ровно столько же символов содержится в таблице кодировки ASCII. Но об этом в другой раз.
На практике пользуются большими значениями объёма памяти килобайтами, мегабайтами, гигабайтами и терабайтами.
1 килобайт (кБ) = 1024 байт
1 мегабайт (МБ) = 1024 кБ
1 гигабайт (ГБ) = 1024 МБ
1 терабайт (ТБ) = 1024 ГБ
Преобразование десятичного числа в двоичное
На практике программисты часто пользуются несколькими системами счисления. Поэтому следует научиться переводить числа из десятичной системы в двоичную. Здесь можно выделить два простых способа. Рассмотрим их по порядку.
Первый способ заключается в том, что десятичное число непрерывно делится на два. При этом учитывается полностью ли оно разделилось или с остатком. Если значение делится без остатка, как например 4/2 = ровно 2 или 6/2 = ровно 3, то записывается ноль, а если с остатком, как 3/2 или 5/2, то записывается единица.
Теперь давайте переведем число 125 в двоичную форму.
125/2 = 62 остаток 1
62/2 = 31 остаток 0
31/2 = 15 остаток 1
15/2 = 7 остаток 1
7/2 = 3 остаток 1
3/2 = 1 остаток 1
1/2 = 0 остаток 1
Получаем двоичное число 11111012
Я надеюсь здесь понятно, что если 1 разделить на 2, то математически ноль никак не получится, однако такой подход позволяет объяснить данный алгоритм.
Еще один пример.
84/2 = 42 остаток 0
42/2 = 21 остаток 0
21/2 = 10 остаток 1
10/2 = 5 остаток 0
5/2 = 2 остаток 1
2/2 = 1 остаток 0
1/2 = 0 остаток 1
Результат 10101002
Второй способ
Второй способ имеет такую идею. С изначального числа нужно вычесть число в степени два, которое будет меньше заданного значения. Для ускорения процесса преобразования воспользуемся следующей таблицей.
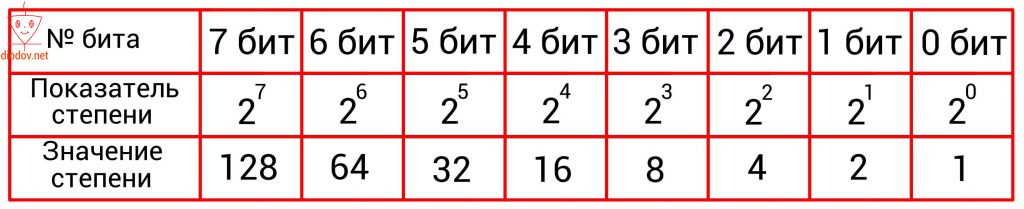
Давайте преобразуем 125.

Наибольшая степень числа 2 меньшая значения 125 равна 6, т.е. 26. Два в шестой степени равно 64. В 6-й бит записываем единицу. Теперь от 125 отнимаем 64 и получаем 61. Ближайшая степень двойки является 5, т. е. число 32. Следовательно, 5-й бит также находится в единице. Отнимаем от 61 значение 32 и получаем 29. 4-й бит, который соответствует числу 16, также находится в единице. 29 – 16 = 13, поэтому и 3-й бит = 1. 13 – 8 = 5. Отсюда видно, что и второй бит находится в единице. Далее от 5 отнимаем 4 и получаем единицу. Поскольку 1-й бит равен двум (21 = 2), а два менее единицы, то в него записываем ноль. Нулевой бит равен одному (20 = 1), поэтому в него заносим единицу. В итоге получаем следующее двоичное число: 11111012.
Следует обратить особое внимание на то, что нумерация битов, во-первых, выполняется справа налево, а во-вторых начинается с нуля! Это несколько непривычно, поскольку в десятичной системе счисления счет принято начинать с единицы. Однако в цифровой технике счет всегда идет с нуля! К этому следует приучить себя заранее, так как при написании программ для микроконтроллеров мы все время будем начинать счет битов с нуля. В дальнейшем вы такому счету быстро привыкнете, поскольку и в техническом описании МК строго соблюдается данное правило.
Преобразование двоичного числа в десятичное
Преобразование двоичного числа в десятичное выполняется довольно просто. Для этого следует сложить десятичные веса всех двоичных разрядов, в которых имеются единицы. Биты, в которых записан ноль, пропускаются. В качестве примера возьмем такое значение: 10101101. Нулевой, второй, третий, пятый и седьмой биты имеют единицы. Получаем: 20 + 22 + 23 + 25 + 27= 1 + 4 +8 + 32 + 128 = 173.
101011012 = 17310
В таблицах, приведенных ниже, наглядно показано перевод чисел из двоичной в десятичную систему счисления.
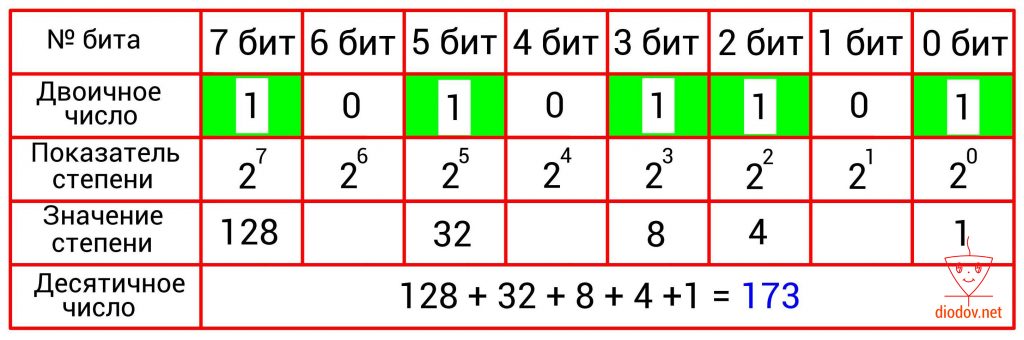
Еще пример.
Шестнадцатеричная система счисления
В программировании микроконтроллеров очень часто пользуются шестнадцатеричными числами. Данная система счисления имеет основание 16, соответственно и 16 различных символов. Первые десять символов 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 заимствованы из десятеричной системы. В качестве оставшихся шести символов применяются буквы A, B, C, D, E, F.
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
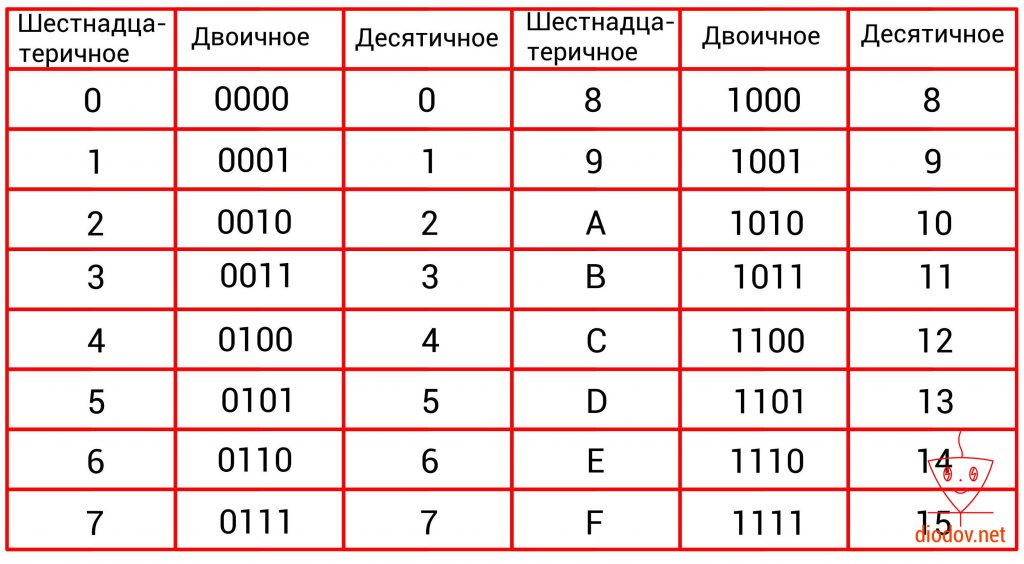
Высокая популярность шестнадцатеричной системы счисления поясняется тем, что при отображении одного и того же значения используется меньше разрядов по сравнению с десятичной системой и тем более с двоичной. Например, при отображении 100 используется три десятичных разряда 10010 или 7 двоичных разрядов 11001002 и только 2 шестнадцатеричных разряда 6416.
10010 = 11001002 = 6416
А если записать 1000000, то разница в количестве занимаемых разрядов буде еще более ощутима:
1 000 00010 = 1111 0100 0010 0100 00002 = F424016
Преобразование двоичного числа в шестнадцатеричное
Еще одним положительным свойством шестнадцатеричного числа является простота получение его из двоичного. Такое преобразование выполняется следующим образом: сначала двоичное число разбивается на группы по четыре быта или на полубайты, которые еще называют тетрадами. Если количество битов не кратно четырем, то их дополняют нулями. Далее следует сложить значение всех битов в каждом полубайте. Сумма каждого полубайта даст значение отдельной цифры шестнадцатеричного числа.
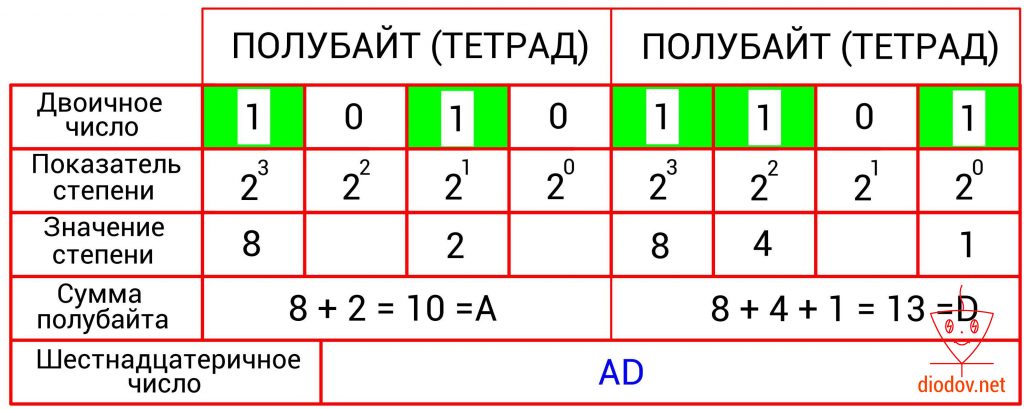
Другие системы счисления
В цифровой технике также применяется восьмеричная система счисления, но она не нашла применения в микроконтроллерах.
Теоретические можно получить бесконечное значение систем счисления: троичную, пятиричную и даже сторичную, т.е. с любым основанием. Однако практической необходимости в этом пока что нет.
Наиболее простой и быстрый способ преобразования чисел с одной системы счисления в другую – это применение встроенного в операционную систему калькулятора. Найти его можно следующим образом: Пуск – Все программы – Стандартные – Калькулятор.
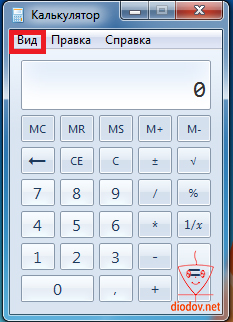
Чтобы перейти в «нужный» режим следует кликнуть по вкладке Вид и выбрать Программист или нажать комбинацию клавиш Alt+3.
В открывшемся окне можно вводить двоичные, восьмеричные, шестнадцатеричные и десятичные числа, выбрав соответствующий режим. Кроме того можно выполнять различные математические операции между ними.
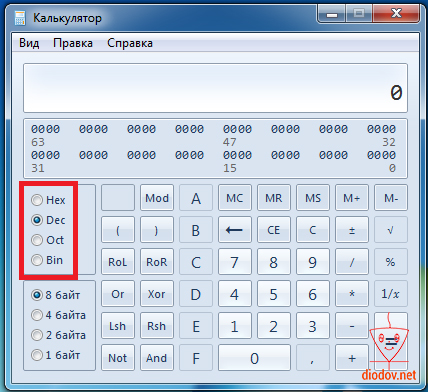
В дальнейшем, при написании кода программы мы часто будем обращаться к данному калькулятору. Кроме того, опытные программисты любят использовать шестнадцатеричные числа, а нам проще будет понять двоичный код, поэтому калькулятор в помощь)

Источник
Автор: © oleg
Рассмотрим,
как в памяти компьютера хранятся
данные.
Вообще, как компьютер может
хранить, например, слово
“диск”? Главный принцип –
намагничивание и размагничивание
одной дорожки (назовем ее так). Одна
микросхема памяти – это, грубо
говоря, огромное количество
дорожек. Сейчас попробуем
разобраться. Например:
нуль будет обозначаться как
0000 (четыре нуля),
один 0001,
два 0010 (т.е. правую единицу
заменяем на 0 и вторую
устанавливаем в 1).
Далее так:
три 0011
четыре 0100
пять 0101
шесть 0110
семь 0111
восемь 1000
девять 1001 и т.д.
Уловили принцип? “0” и “1”
– это т.н. биты. Один бит, как вы уже
заметили, может быть нулем или
единицей, т.е. размагничена или
намагничена та или иная дорожка
(“0” и “1” это условное
обозначение). Если еще
присмотреться, то можно заметить,
что каждый следующий установленный
бит (начиная справа) увеличивает
число в два раза: 0001 в нашем примере
= 1; 0010 два; 0100 четыре; 1000 восемь и т.д.
Это и есть т.н. двоичная форма
представления данных.
Т.о. чтобы обозначить числа от 0 до
9 нам нужно четыре бита (хоть они и
не до конца использованы. Можно
было бы продолжить: десять 1010,
одиннадцать 1011 , пятнадцать 1111).
Компьютер хранит данные в памяти
именно так. Для обозначения
какого-нибудь символа (цифры, буквы,
запятой, точки…) в компьютере
используется определенное
количество бит. Компьютер
“распознает” 256 (от 0 до 255)
различных символов по их коду.
Этого достаточно, чтобы вместить
все цифры (0 – 9), буквы латинского
алфавита (a – z, A – Z), русского (а – я, А –
Я), а также другие символы. Для
представления символа с
максимально возможным кодом (255)
нужно 8 бит. Эти 8 бит называются
байтом. Т.о. один любой символ –
это всегда 1 байт (см. рис. 1).
1 | 1 | 1 | 1 | ||||
р | н | р | н | н | р | н | р |
Рис. 1. Один байт с
кодом буквы Z
(буквы н и р
обозначают: намагничено или
размагничено соответственно)
Можно элементарно проверить.
Создайте в текстовом редакторе
файл с любым именем и запишите в нем
один символ, например, “М” (но
не нажимайте Enter!). Если вы
посмотрите его размер, то файл
будет равен 1 байту. Если ваш
редактор позволяет смотреть файлы
в шестнадцатеричном формате, то вы
сможете узнать и код сохраненного
вами символа. В данном случае буква
“М” имеет код 4Dh в
шестнадцатеричной системе, которую
мы уже знаем или 1001101 в двоичной.
Т.о. слово “диск” будет
занимать 4 байта или 4*8 = 32 бита. Как
вы уже поняли, компьютер хранит в
памяти не сами буквы этого слова, а
последовательность “единичек”
и “ноликов”. “Почему же тогда
на экране мы видим текст, а не
“единички-нолики”? – спросите
вы. Чтобы удовлетворить ваше
любопытство, я забегу немного
вперед и скажу, что всю работу по
выводу самого символа на
экран (а не битов) выполняет
видеокарта (видеоадаптер), которая
находится в вашем компьютере. И
если бы ее не было, то мы,
естественно, ничего бы не видели,
что у нас творится на экране.
В Ассемблере после двоичного
числа всегда должна стоять буква
“b”. Это нужно для того, чтобы
при ассемблировании нашей
программы Ассемблер смог отличать
десятичные, шестнадцатеричные и
двоичные числа. Например: 10 – это
“десять”, 10h – это
“шестнадцать” а 10b – это
“два” в десятичной системе.
Т.о. в регистры можно загружать
двоичные, десятичные и
шестнадцатеричные числа.
Например:
mov ax,20
mov bh,10100b
mov cl,14h
В результате в регистрах AX, BH и CL
будет находится одно и тоже число,
только загружаем мы его в разных
системах. Компьютер же будет
хранить его в двоичном формате (как
в регистре BH).
Итак, подведем итог. В
компьютере вся информация хранится
в двоичном формате (двоичной
системе) примерно в таком виде: 10101110
10010010 01111010 11100101 (естественно, без
пробелов. Для удобства я разделили
биты по группам). Восемь бит – это
один байт. Один символ занимает
один байт, т.е. восемь бит. По-моему,
ничего сложного. Очень важно
уяснить данную тему, так как мы
будем постоянно пользоваться
двоичной системой, и вам необходимо
знать ее на “отлично”.
Как перевести
двоичное число в десятичное:
Надо сложить двойки в степенях,
соответствующих позициям, где в
двоичном стоят единицы. Например:
Возьмем число 20. В двоичной
системе оно имеет следующий вид:
10100b
Итак (начнем слева направо, считая
от 4 до 0; число в нулевой степени
всегда равно единице (вспоминаем
школьную программу по математике)):
10100b = 1*24 + 0*23 + 1*22 +
0*21 + 0*20 = 20
——————————————————–
16+0+4+0+0 = 20
Как перевести
десятичное число в двоичное:
Можно делить его на два, записывая
остаток справа налево:
20/2 = 10, остаток
10/2=5, остаток
5/2=2, остаток 1
2/2=1, остаток
1/2=0, остаток 1
В результате получаем: 10100b
= 20
Как перевести
шестнадцатеричное число в
десятичное:
В шестнадцатеричной системе
номер позиции цифры в числе
соответствует степени, в которую
надо возвести число 16:
8Ah = 8*16 + 10 (0Ah) = 138
В настоящий момент есть множество
калькуляторов, которые могут
считать и переводить числа в разных
системах счисления. Например,
калькулятор Windows, который должен
быть в инженерном виде. Очень
удобен калькулятор и в DOS Navigator’е.
Если у вас есть он, то отпадает
необходимость в ручном переводе
одной системы в другую, что,
естественно, упростит вам работу.
Однако, знать этот принцип крайне
важно!
________________
Сегментация
памяти в DOS.
Возьмем следующее предложение:
“Изучаем сегменты памяти”.
Теперь давайте посчитаем, на каком
месте стоит буква “ы” в слове
“сегменты” от начала
предложения включая пробелы… На
шестнадцатом. Подчеркну, что мы
считали слово от начала
предложения.
Теперь немного усложним задачу и
разобьем предложение следующим
образом (символом “_” обозначен
пробел):
Пример N 1:
0000: Изучаем_
0010: сегменты_
0020: памяти
0030:
В слове “Изучаем”
символ “И” стоит на нулевом
месте; символ “з” на первом,
“у” на втором и т.д. В данном
случае мы считаем буквы начиная с
нулевой позиции, используя два
числа. Назовем их сегмент и смещение.
Тогда, символ “ч” будет иметь
следующий адрес: 0000:0003, т.е. сегмент
0000, смещение 0003. Проверьте…
В слове “сегменты”
будем считать буквы начиная с
десятой позиции, но с нулевого
смещения. Тогда символ “н”
будет иметь следующий адрес: 0010:0005,
т.е. пятый символ начиная с десятой
позиции. 0010 – сегмент, 0005 смещение.
Тоже проверьте…
В слове “память”
считаем буквы начиная с 0020 сегмента
и также с нулевой позиции. Т.о.
символ “а” будет иметь аодрес
0020:0001, т.е. сегмент 0020, смещение 0001.
Опять проверим…
Итак, мы выяснили, что для того,
чтобы найти адрес нужного символа
необходимо два числа: сегмент
и смещение внутри этого сегмента.
В Ассемблере сегменты хранятся в
сегментных регистрах: CS, DS, ES, SS , а
смещения могут храниться в других
(но не во всех).
Регистр CS служит для хранения
сегмента кода программы (Code
Segment – сегмент кода);
Регистр DS для хранения сегмента
данных (Data Segment –
сегмент данных);
Регистр SS для хранения сегмента
стека (Stack Segment –
сегмент стека);
Регистр ES дополнительный
сегментный регистр, который может
хранить любой другой сегмент
(например, сегмент видеобуфера).
Пример N 2:
Давайте попробуем загрузить в
пару регистров ES:DI сегмент и
смещение буквы “м” в слове
“памяти” из примера N 1 (см.
выше). Вот как это запишется на
Ассемблере:
(1) mov ax,0020
(2) mov es,ax
(3) mov di,2
Теперь в регистре ES находится
сегмент с номером 20, а регистре DI
смещение к букве “м” в слове
“памяти”. Проверьте,
пожалуйста…
Здесь стоит отметить, что
загрузка числа (т.е. какого-нибудь
сегмента) напрямую в сегментый
регистр запрещена. Поэтому мы в
строке (1) загрузили сегмент в AX, а в
строке (2) загрузили в регистр ES
число 20, которое находилось в
регистре AX:
mov ds,15 —> ошибка!
mov ss,34h —> ошибка!
Когда мы загружаем программу в
память, она автоматически
располагается в первом свободном
сегменте. В файлах типа *.com все
сегментные регистры автоматически
инициализируются для этого
сегмента (устанавливаются значения
равные тому сегменту, в который
загружена программа). Это можно
проверить при помощи отладчика.
Если, например, мы загружаем
программу типа *.com в память, и
компьютер находит первый свободный
сегмент с номером 5674h, то сегментные
регистры будут иметь следующие
значения:
CS = 5674h
DS = 5674h
SS = 5674h
ES = 5674h
Код программы типа *.com должны
начинаться со смещения 100h. Для
этого мы, собственно, и ставили в
наших прошлых примерах программ
оператор org 100h, указывая Ассемблеру
при ассемблировании использовать
смещение 100h от начала сегмента, в
который загружена наша программа
(позже мы рассмотрим для чего это
нужно). Сегментные же регистры, как
я уже говорил, автоматически
принимают значение того сегмента, в
который загрузилась наша
программа.
Пара регистров CS:IP задает текущий
адрес кода. Теперь рассмотрим, как
все это происходит на конкретном
примере:
Пример N 3.
(1) CSEG segment
(2) org 100h
(3) _start:
(4) mov ah,9
(5) mov dx,offset My_name
(6) int 21h
(7) int 20h
(8) My_name db ‘Oleg$’
(9) CSEG ends
(10) end _start
Итак, строки (1) и (8) описывают
сегмент: CSEG (даем имя сегменту) segment
(оператор Ассемблера, указывающий,
что имя CSEG – это название сегмента);
CSEG ends (end segment – конец
сегмента) указывает Ассемблеру на
конец сегмента.
Строка (2) сообщает, что код
программы (как и смещения внутри
сегмента CSEG) необходимо
отсчитывать с 100h. По этому адресу в
память всегда загружаются
программы типа *.com.
Запускаем программу из Примера N 3
в отладчике. Допустим, она
загрузилась в свободный сегмент
1234h. Первая команда в строке (4) будет
располагаться по такому адресу:
1234h:0100h (т.е. CS = 1234h, а IP = 0100h)
(посмотрите в отладчике на регистры
CS и IP).
Перейдем к следующей команде (в
отладчике CodeView нажмите клавишу F8, в
другом посмотрите какая клавиша
нужна; будет написано что-то вроде
“F8-Step”). Теперь вы видите, что
изменились следующие регистры:
AX = 0900h (точнее, AH = 09h, а AL = 0, т.к. мы
загрузили командой mov ah,9 число 9 в
регистр AH, при этом не трогая AL. Если
бы AL был равен, скажем, 15h, то после
выполнения данной команды AX бы
равнялся 0915h)
IP = 102h (т.е. указывает на адрес
следующей команды. Из этого можно
сделать вывод, что команда mov ah,9
занимает 2 байта: 102h – 100h = 2).
Следующая команда (нажимаем
клавишу F8) изменяет регистры DX и IP.
Теперь DX указывает на смещение
нашей строки (“Oleg$”)
относительно начала сегмента, т.е.
109h, а IP равняется 105h, т.е. адрес
следующей команды. Нетрудно
посчитать, что команда mov dx,offset My_name
занимает 3 байта (105h – 102h = 3).
Обратите внимание, что в
Ассемблере мы пишем:
mov dx,offset My_name
а в отладчике видим следующее:
mov dx,109 (109 – шестнадцатеричное
число, но CodeView символ ‘h’ не ставит.
Это надо иметь в виду).
Почему так происходит? Дело в том,
что при ассемблировании программы,
Ассемблер подставляет вместо offset
My_name реальный адрес строки с именем
My_name в памяти. Можно, конечно,
записать сразу
mov dx,109h
Программа будет работать
нормально. Но для этого нам нужно
высчитать самим этот адрес.
Попробуйте вставить следующие
команды, начиная со строки (7) в
примере N 3:
(7) int 20h
(8) int 20h
(9) My_name db ‘Oleg$’
(10) CSEG ends
(11) end _start
Просто продублируем команду int 20h
(хотя, как вы уже знаете, до строки (8)
программа не дойдет).
Теперь ассемблируйте программу
заново. Запускайте ее под
отладчиком. Вы увидите, что в DX
загружается не 109h, а другое число.
Подумайте, почему так происходит.
Это просто!
В окне “Memory” (“Память”) вы
должны увидеть примерно такое:
1234:0000 CD 20 00 A0 00 9A F0 FE = .a.
|N1_|_N2_| |_________N3__________| |N4_|
Позиция N1 (1234) – сегмент, в
который загрузилась наша программа
(может быть любым).
Позиция N2 (0000) – смещение в
данном сегменте (сегмент и смещение
отделяются двоеточием (:)).
Позиция N3 (CD 20 00 … F0 FE) – код в
шестнадцатеричной системе, который
располагается с адреса 1234:0000.
Позиция N4 (= .a.) – код в ASCII (ниже
рассмотрим), соответствующий
шестнадцатеричным числам с правой
стороны.
В Позиции N2 (смещение) введите
значение, которое находится в
регистре DX после выполнения строки
(5). После этого в Позиции N4 вы
увидите строку “Oleg$”, а в
Позиции N3 – код символов “Oleg$” в
шестнадцатеричной системе… Вот
что загружается в DX! Это не что иное,
как АДРЕС (смещенеие) нашей строки в
сегменте!
Но вернемся. Итак, мы загрузили в DX
адрес строки в сегменте, который мы
назвали CSEG (строки (1) и (9) в Прмере N
3). Теперь переходим к следующей
команде: int 21h. Вызываем прерывание
DOS с функцией 9 (mov ah,9) и адресом
строки в DX (mov dx,offset My_name).
Как я уже говорил раньше, для
использования прерываний в
программах, в AH заносится номер
функции. Номера функций нужно
запоминать.
Наше первое
прерывание.
Функция 09h прерывания 21h выводит
строку на экран, адрес которой
указан в регистре DX.
Вообще, любая строка, состоящая из
ASCII символов, называется ASCII-строка.
ASCII символы – это символы от 0 до 255 в
DOS, куда входят буквы русского и
латинского алфавитов, цифры, знаки
препинания и пр.
Изобразим это в таблице (так
всегда теперь будем делать):
Функция 09h прерывания
21h – вывод строки символов на экран в
текущую позицию курсора:
| Вход: | AH = 09h DX = адрес ASCII-строки |
| Выход: | ничего |
В поле “Вход”
мы указываем, в какие регистры что
загружать, а в поле “Выход”
– что возвращает функция. Сравните
эту таблицу с Примером N 3.
_____________________
Вот мы и рассмотрели сегментацию
памяти. Если я что-то упустил, то это
рассмотрим в последующих выпусках.
Очень надеюсь на то, что вы
разобрались в данной теме.
Теперь интересная программка для
практики, которая выводит в верхний
левый угол экрана веселую рожицу на
синем фоне:
(1) CSEG segment
(2) org 100h
(3) _beg:
(4) mov ax,0B800h
(5) mov es,ax
(6) mov di,0
(7)
(8) mov ah,31
(9) mov al,1
(10) mov es:[di],ax
(11)
(12) mov ah,10h
(13) int 16h
(14)
(15) int 20h
(16)
(17) CSEG ends
(18) end _beg
Многие операторы вы уже знаете.
Поэтому я буду объяснять только
новые.
В данном примере мы используем
вывод символа прямым отображением
в видеобуфер.
В строках (4) и (5) загружаем в
сегментный регистр ES число 0B800h,
которое соответствует сегменту
дисплея в текстовом режиме
(запомните его!). В строке (6)
загружаем в регистр DI нуль. Это
будет смещение относительно
сегмента 0B800h. В строках (8) и (9) в
регистр AH заносится атрибут
символа (31 – ярко-белый символ на
синем фоне) и в AL – ASCII-код символа (01 –
это рожица) соответственно.
В строке (10) заносим по адресу
0B800:0000h (т.е. первый символ в первой
строке дисплея – верхний левый угол)
атрибут и ASCII-код символа (31 и 01
соответственно) (сможете
разобраться?).
Обратите внимание на запись
регистров в строке (10). Скобки ( [ ] )
указывают на то, что надо загрузить
число не в регистр, а по адресу,
который содержится в регистре (в
данном случае, как уже отмечалось, –
это 0B800:0000h).
Можете поэксперементировать с
данным примером. Только не меняйте
строки (4) и (5). Сегментный регистр
должен быть ES (можно, конечно, и DS, но
тогда надо быть осторожным). Более
подробно данный метод рассмотрим
позже. Сейчас нам из него нужно
понять принцип сегментации на
практике.
Следует отметить, что
вывод символа прямым отображением
в видеобуфер является самым
быстрым. Выполнение команды в
строке (10) занимает 3 – 5 тактов. Т.о.
на Pentium-100Mhz можно за секунду вывести
20 миллионов(!) символов или
чуть меньше точек на экран! Если бы
все программисты (а особенно Microsoft)
выводили бы символы или точки на
экран методом прямого отображения
в видеобуфер на Ассемблере, то
программы бы работали чрезвычайно
быстро… Я думаю, вы представляете…
Литература по Assembler
Источник